By Priyadarshini Shetty, Founder of Walchet
Large Language Models (LLMs) have the potential to transform the practice of law in many different ways, let’s start by understanding what they are.
LLMs are a type of Artificial Intelligence that have been trained on textual data. This training is used to generate new text as an output in a human-like fashion. LLMs can help with summarising, drafting and extracting text on a variety of data including contracts, cases and legislation, based on questions or tasks inputted into the system (prompts).
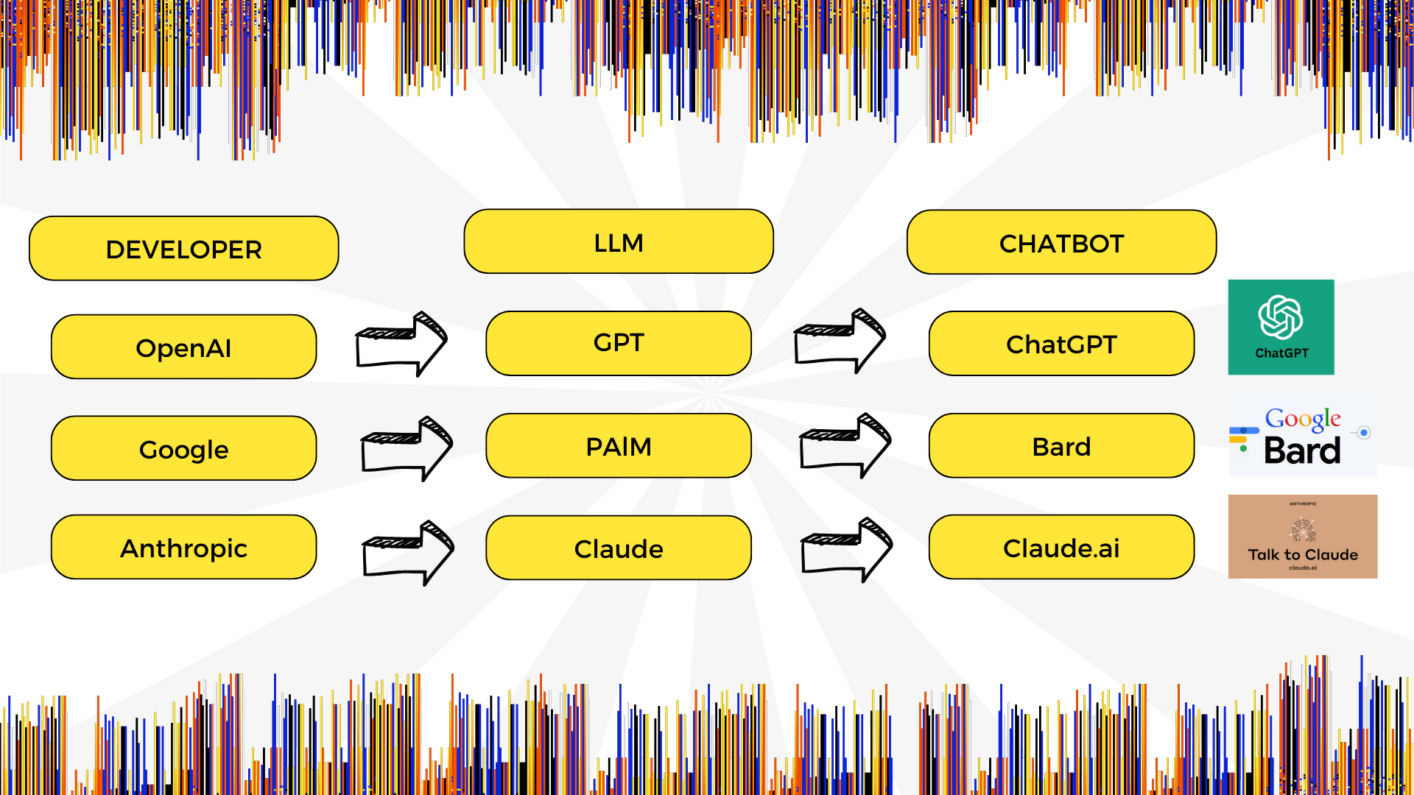
We interact (provide instructions and receive responses) with an LLM through a chatbot. Sometimes the developer of the LLM has their own chatbot and sometimes you can build your own chatbot on top of the LLM. Some examples of LLMs that have their own corresponding chatbots are set out below.
Prompts are instructions/ questions written in plain language (not code) and given to the LLM to guide its output. Examples of prompts inputted into an LLM could be “In which judgement did the Supreme Court establish the basic structure doctrine?” or even an open-ended instruction like “Draft a buyer-friendly indemnity clause.”
Today, lots of legal teams are exploring how they can deploy LLMs on their proprietary data, ensuring that the appropriate LLM can generate responses based on their internal data so that information is easily accessible to their lawyers. Here are 5 tips to consider when exploring how to run an LLM on your data.
1. Be LLM Agnostic
There are several LLMs in the market (Claude, Bard, Cohere etc.), take the time to choose which LLM will be most suitable for your purpose. While the core functionality of an LLM will be similar across the board, their performance against different applications can be quite different. For instance some LLMs may be better at certain tasks (like summarization) and some other LLMs may be better at other tasks (like text classification and extraction). Accordingly, depending on the desired task/ use case, the choice of LLM may differ. It is always helpful to conduct a pilot of the specific task with different LLMs to see which one is most suitable.
2. Clean your data
Responses generated by an LLM is as good as the data it is trained on. So if you are looking for accurate responses based on your proprietary data, it is important to ensure that your data is machine readable and structured. Poor quality scans, handwriting/ stamps over printed data and images interrupting or obscuring text all make data difficult to read. Running an OCR (Optical Character Recognition) function on your data makes it searchable (you can do a Ctrl+F). Structured data refers to data that is organized in a predefined format. If your data is unorganized, you need to first sort through the data. You can do this manually or with the help of software tools. This involves grouping similar data together, in an organized manner. For instance, maybe you want all your supplier contracts to be in one folder, or you want all data relating to a specific vendor in one folder and then sub-categorised date wise. Identify the desired format for organizing your data. The more structured your data is, the easier it becomes for an LLM or any tool to process that data.
3. Fine Tuning
An LLM is not going to work with high levels of accuracy right out of the box. This is because LLMs have been trained on generic data and not data specific to the legal industry. Accordingly, before you start relying on the responses, you need to first expose the LLM to legal data for the purpose of fine
tuning. Legal data could be generic legal data (contracts, legislation or jurisprudence) or your organisation’s proprietary data or both.
4. Guardrails
LLMs do not always know the accurate response to every question, and sometimes they may provide an incorrect or misleading response. This is known as a hallucination. If the LLM cannot find the answer to a question, it is able to create an answer that may appear accurate but is not. As a lawyer, this is problematic. Accordingly, explore whether you can build guardrails into the LLM, to prevent it from hallucinating. This could include the LLM hyperlinking the source to its response or simply responding that it does not know the answer to the query because it cannot find it within the dataset provided. Some LLMs may have an in-built functionality for this, but if not, then explore whether or not you can build it on your own.
5. Security Parameters
A lot of legal data is confidential, privileged or both. Accordingly, data security is a paramount concern when using an LLM, as you want to ensure that your data is secure. Sometimes you may be able to source the foundational model of the LLM on your local servers ensuring that data does not need to leave your organization. Alternatively, the LLM itself (like ChatGPT Enterprise) can have security parameters built in to safeguard your data. Review the security parameters of the LLM carefully to assess whether it matches your internal requirements.
Effectively using an LLM on your proprietary data is never going to be a quick fix, and depending on the use case you are trying to solve for, it could take several months of training before you can expect to receive desired levels of accuracy. Properly planning for the above considerations will go a long way in ensuring a smooth roll out of an LLM at your organisation.
About the author –
Priyadarshini Shetty is a legal tech and innovation expert. She is the founder of Walchet, a legal technology and innovation content initiative, where she creates content for legal professionals and teams to advocate about the potential to grow and improve their practice through the adoption of innovative techniques and legal tech solutions.